“Google文件存储系统(GFS)是构建在廉价服务器之上的大型分布式系统。它将服务器故障视为正常现象,通过软件方式自动容错,在保证系统可用性和可靠性同时,大大降低系统成本。
GFS是Google整个分布式系统的基石,其他存储系统如Google BigTable、GoogleMegastore等系统均直接或间接构建在GFS之上。另外,Google的大规模批处理系统MapReduce也是利用GFS系统作为海量数据的输入输出。”
以下内容为在研读Google_File_System论文时,对其中一些关键技术的理解。要想更加深入的理解GFS,还需进一步研究GFS源码以及论文等。
一、单一Master节点:
如何避免单一的Msaster节点成为系统性能瓶颈:
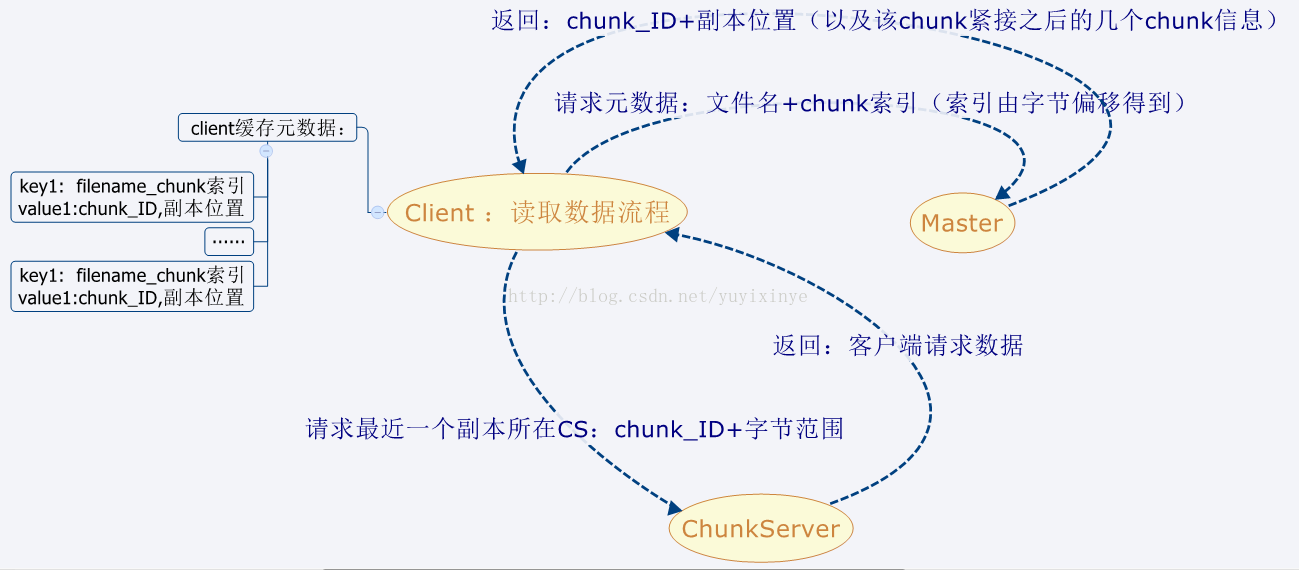
- 客户端只向Master请求元数据信息,并不通过Master节点进行chunk数据读写,具体的数据读写操作由ChunkServer直接负责。
- 客户端在向Master请求某chunk元数据时,Master会一次返回包括该chunk紧接之后的几个chunk信息,有效减少客户端的请求次数。
客户端读取数据流程如下:
二、Chunk尺寸:
选择64MB作为chunk的大小,该尺寸远大于一般系统的Block size。这是由具体的业务特性决定的:即通常操作的是大文件。

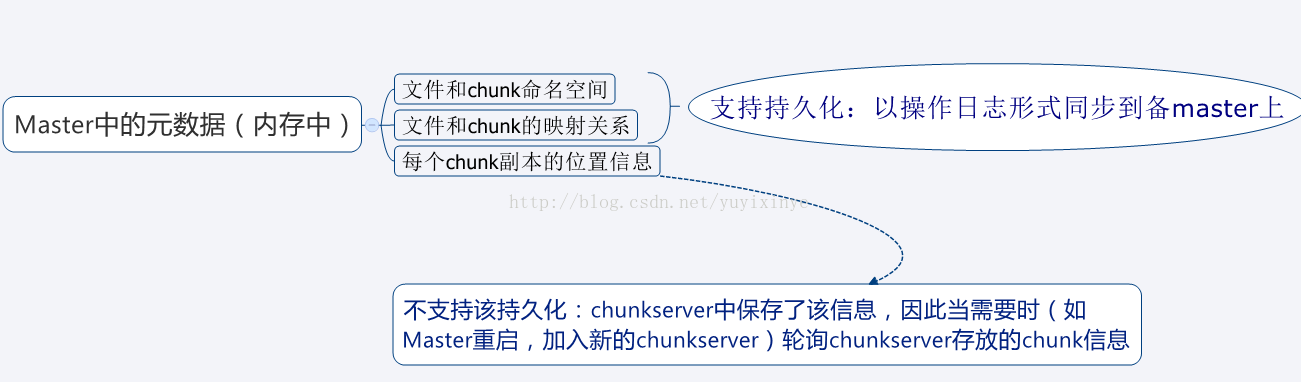
三、Master元数据:
Master以心跳信息来监控chunkserver的状态。 其中,chunk的副本位置信息,采取启动master时轮询(心跳信息)chunkserver,然后定期轮询来获取chunk的副本位置信息,而不是直接在master中持久化该信息。 这样简化了Master与chunkserver之间的的数据同步问题。
操作日志:
强同步:即只有当操作日志被写入到本地磁盘以及远程机器(备master)磁盘后,才会响应客户端的操作请求。同时master会收集多个日志后,批量写入磁盘。
checkpoint: 在灾难恢复时通过回放操作日志来将系统恢复到最近状态。为了减低回放时间,使用checkpoint方式来使得回放的日志尽量短,即在恢复时只需要回放checkpoint之后的日志文件即可。之前的旧日志文件及checkpoint文件可定期删除。“操作日志相当于一盘录像带,而checkpoint可以在该录像带上间隔性的插上一些标记点(将内存缓冲的数据写入磁盘,完成后,相应的在操作日志带上插入最新的一个标记点)。最新一个标记点之前的所有日志记录的操作都已经持久化保存了,而该点之后的操作保存在内存中。当内存中数据丢失时,只需回放该点之后的部分日志即可恢复。而checkpoint文件就是记录了这些点的位置等信息。”
四、系统交互:
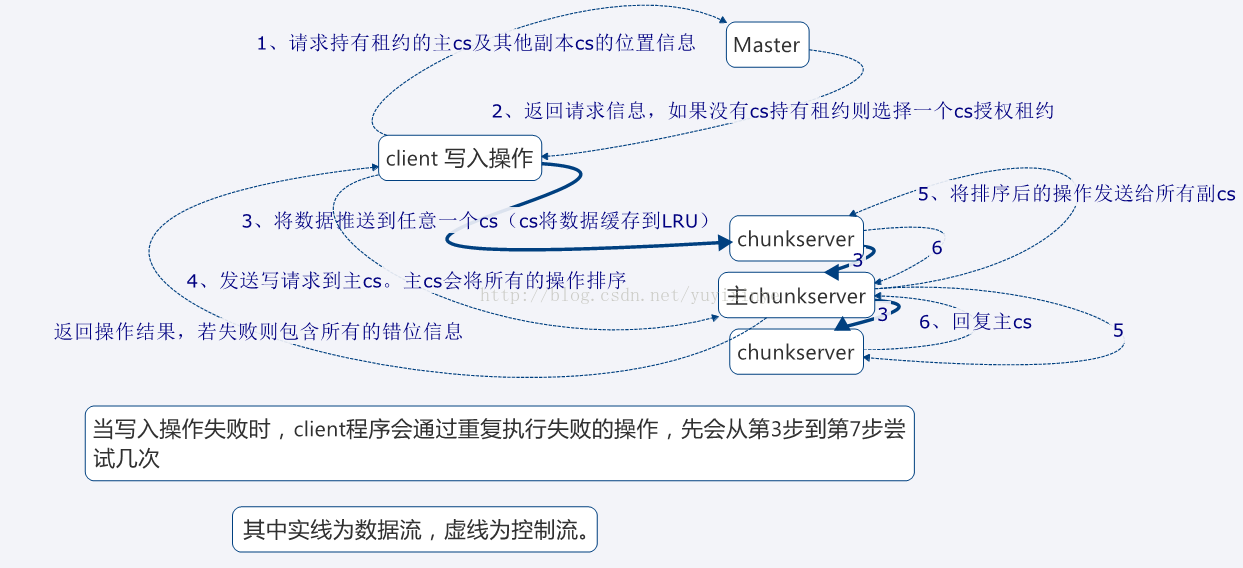
Master以带超时的租约来授权主chunkserver来执行具体的操作任务,从而减小Master的管理负担。Master与chunkserver之间通过定期的心跳信息来交互信息:master获取chunkserver’的状态信息,chunkserver申请延长租约时间等。
以下为客户端写数据的操作流程:
五、负载均衡:

本文地址:http://xnerv.wang/the-google-file-system-paper-analysis/
转载自:The Google File System——论文详解