关于PageRank的基础知识简介请参见博文:《深入探讨PageRank(一):PageRank算法原理入门》。
一、PageRank算法的简单举例
Google PageRank算法的思想精华在于:将一个网页级别/重要性的排序问题转化成了一个公共参与、以群体民主投票的方式求解的问题,网页之间的链接即被认为是投票行为。同时,各个站点投票的权重不同,重要的网站投票具有较大的分量,而该网站是否重要的标准还需要依照其PageRank值。这看似是一个矛盾的过程:即我们需要用PageRank值来计算PageRank值。
听起来有点不可思议,既像是递归,又像是迭代,似乎陷入了一个漩涡,Google的创始人佩奇和布林证明了这个过程最终收敛值与初始值无关。遗憾的是我一直都没有找到这个证明,甚至我把佩奇他们当年那篇论文找出来看也没有发现。
对于PageRank的收敛性,我们是可以找到反例的,这说明PageRank至少在某些情况下是不可能收敛的,或者说是收敛不完备的。在本文的第三部分,我们将PageRank的问题转化为了马尔可夫链的概率转移问题,其收敛性的证明也即转化为了马氏链的平稳分布是否存在的证明。我们先来看一个简单的例子:
Google PageRank取值范围是010,为了叙述方便,我们使用01的区间作为度量,这并不会影响我们对PageRank原理的剖析,并且在初始化的时候,我们假设所有网站的PageRank的值是均匀分布的。这意味着,如果有N个网站,那么每个网站的PageRank初始值都是1/N。现在假设有4个网站A、B、C、D,则它们的初始PageRank都是0.25,它们的链接关系如下:
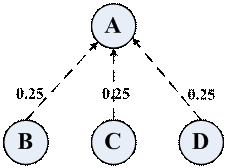
则初始值PR(A) = PR(B) = PR© = PR(D) = 0.25,又因为B、C、D都有指向A的链接,因此,它们每人都为A贡献了0.25的PageRank值,重新计算A的PageRank值为:PR(A) = PR(B) + PR© + PR(D) = 0.75,由于B、C和D并没有外部链接指向它们,因此PR(B)、PR©、PR(D)在这次计算中将被赋值为0。反复套用PageRank的计算公式,来看一下,这种情况下PageRank的收敛性,在第二次迭代之后,所有的PageRank值就都是0了:
| PageRank | PR(A) | PR(B) | PR© | PR(D) |
|---|---|---|---|---|
| 初始值 | 0.25 | 0.25 | 0.25 | 0.25 |
| 第一次迭代后 | 0.75 | 0 | 0 | 0 |
| 第二次迭代后 | 0 | 0 | 0 | 0 |
我们来分析一下这个例子PageRank收敛的情况,由于没有网站链接到D,那么第一次迭代之后PR(D)=0,这将导致PR(B)=0,继而导致PR©=0和PR(A)=0。
现在来看第个例子,假设网站B还有C链接,网站D上有其他三个网站的链接。对于B而言的话,它把自己的总价值分散投给了A和C,各占一半的PageRank,即0.125,C和D的情况同理。即一个网站投票给其它网站PageRank的值,需要除以它所链接到的网站总数。此时PageRank的计算公式为:
1 | PR(A) = PR(B) / 2 + PR(C) / 1 + PR(D) / 3 |
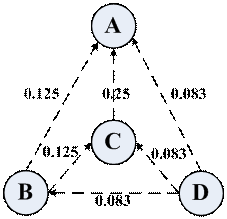
| PageRank | PR(A) | PR(B) | PR© | PR(D) |
|---|---|---|---|---|
| 初始值 | 0.25 | 0.25 | 0.25 | 0.25 |
| 第一次迭代后 | 0.4583 | 0.0833 | 0.2083 | 0 |
| 第二次迭代后 | 0.25 | 0 | 0.0417 | 0 |
| 第三次迭代后 | 0.417 | 0 | 0 | 0 |
| 第四次迭代后 | 0 | 0 | 0 | 0 |
PageRank值计算过程的一般步骤可以概括如下:
- 为每个网站设置一个初始的PageRank值。
- 第一次迭代:每个网站得到一个新的PageRank。
- 第二次迭代:用这组新的PageRank再按上述公式形成另一组新的PageRank。
……
当然,我们最关心的问题是,如此迭代下去,这些PageRank的值最终会收敛吗?我们上述的两个例子都是收敛的,但是不是所有情况都是如此呢?而且,上述例子中,我们发现,一旦某个页面的外部链接数目为0的话,那必然将导致全部网页最终收敛值为0。
二、PageRank算法的“黑洞效应”
为了讨论收敛性的问题,我们暂时抛开具体的网站,把问题做一个抽象化的描述,我们可以把网页之间的关联关系理解为是若干张有向图,图与图之间是互不连通的,那我们只考虑每一部分的收敛性,并不会影响其他部分的收敛性。我们考虑把边权值当作网站所传递的PageRank值,则对于任意一个顶点而言,其出边的权值之和必为1。
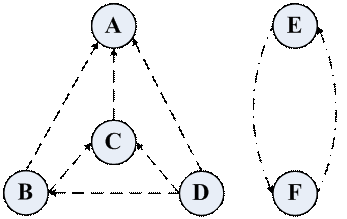
一个很显然的结论是,如果连通图中有一个顶点的入度为0,则经过有限次迭代之后,该连通图内的所有顶点的PageRank均为0,形象的说,这个顶点就像一个黑洞一样,把整体的PageRank值慢慢地“吸收”了。由于它不对外贡献任何PR值,所以整体的PR总和是在不断地减少,直到最终收敛到0。我把它称之为:PageRank的“黑洞效应”。至于说Google是如何防止这种情况的发生,毕竟一个网站没有外链是完全有可能的,我也尚未找到确切的答案。不过网上道是有人给出了一种解决办法:即如果一个网站没有外链,那么就假定该连通图内其余所有的网点都是它的外链,这样我们就避免了整体PageRank值被吸收的现象。
当一个连通图内部每一个顶点入度均大于0时,不难看出,PR值在内部流通过程中,整体的PR值是守恒的。如果是存在一个顶点的入度为0呢?通过一次迭代,它的PR值就会变成0,而把它的那部分PR值贡献给了图中剩余的部分。所以,最终入度为0的顶点的PR值都将是0,而整体的PR仍然守恒。那么整体的PR值守恒就一定能够保证每个顶点的PR值最终会收敛吗?下面看一个简单的例子:
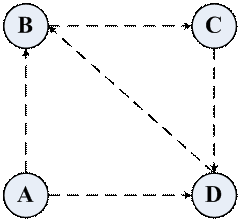
按照之前的迭代步骤,会得到一个迭代的结果表。这将是一个无限循环,且不会收敛的过程。
| PageRank | PR(A) | PR(B) | PR© | PR(D) |
|---|---|---|---|---|
| 初始值 | 0.25 | 0.25 | 0.25 | 0.25 |
| 第一次迭代后 | 0 | 0.375 | 0.25 | 0.375 |
| 第二次迭代后 | 0 | 0.375 | 0.375 | 0.25 |
| 第三次迭代后 | 0 | 0.25 | 0.375 | 0.375 |
| 第四次迭代后 | 0 | 0.375 | 0.25 | 0.375 |
| 第五次迭代后 | 0 | … | … | … |
其实,同样的问题我们还可以换一个角度来考虑,因为本质上有向图和矩阵是可以相互转化的,令A[i][j]表示从顶点i到达顶点j的概率,那么目力的矩阵表示就是:
1 | 0 0.5 0 0.5 |
而我们所给定的初始向量是:(0.25 0.25 0.25 0.25),做第一次迭代,就相当于用初始向量乘以上面的矩阵。第二次迭代就相当于第一次迭代的结果再乘以上面的矩阵……实际上,在随机过程理论中,上述矩阵被称为“转移概率矩阵”。这种离散状态按照离散时间的随机转移过程称为马氏链(马尔可夫链,Markov Chain)。设转移概率矩阵为P,若存在正整数N,使得P^N>0(每个元素大于0),这种链被称作正则链,它存在唯一的极限状态概率,并且与初始状态无关。
在这里,我们仅仅是非常简单地讨论了一下PageRank的原理,这与Google PageRank的实际算法实现相当甚远。域名数据、内容质量、用户数据、建站时间等都有可能被考虑进去,从而形成一个完善的算法。
当然,最让人惊叹的是,Google的PageRank能够应对互联网所产生的如此海量的网页信息和实时的变化,并能够在有限的时间内计算出所有网站的PageRank!这里面到底蕴涵着什么样的奥秘,我也会继续地追寻下去!
三、PageRank算法的马尔科夫过程分析
从第二节的陈述中我们知道,事实上,PageRank值在转移过程中变化规律是完全可以用马尔科夫的状态转移来进行表征的,两者本质属于同一个问题。则当PageRank值收敛时,即为马尔可科夫链达到平衡分布。推荐大家去读《随机过程》的教材,这里不在详细地讨论马氏链的内容,只给出相应的结论。
为了形象说明马氏链,这里举一个例子。假设一{A, B, C}为马氏链,其转移概率矩阵如下所示:
1 | 0.7 0.1 0.2 |
因为该马氏链是不可约的非周期的有限状态,平稳分布存在,则我们要求其平衡分布为:
1 | X = 0.7X + 0.1Y + 0.05Z |
解得上述方程组的平稳分布为:X = 0.1765,Y = 0.2353,Z = 0.5882。
既然,说我们把PageRank收敛性问题转化为了求马尔可夫链的平稳分布的问题,那么我们就可以从马氏链的角度来分析问题。因此,对于PageRank的收敛性问题的证明也就迎刃而解了,只需要证明马氏链在什么情况下才会出现平稳分布即可。我们可以知道马氏链有三个推论:
推论1. 有限状态的不可约非周期马尔可夫链必存在平稳分布。
推论2. 若不可约马尔可夫链的所有状态是非常返或零常返的,则不存在平稳分布。
推论3. 若{Xi}是不可约的非周期马氏链的平稳分布,则lim(n→∞)Pj(n) = Xi。
上面的三个推论看不懂不要紧,找本《随机过程》的书就明白了,这里不再详细讨论了。既然问题得以转化,那么我们还计算一个实例,看看PageRank是如何工作的。假设这里有相互链接关系的7个HTML网页,并且HTML网页之间的链接关系闭合于这1~7个网页中,也即是说,除了这些网页之外,没有任何链接的出入。
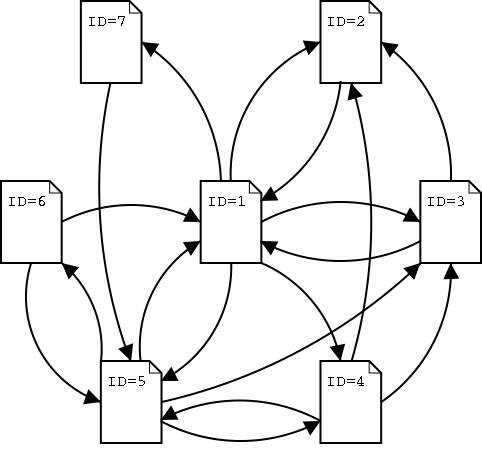
那么我们可以很容易地将这个链接关系使用数学的方式表示出来。首先,分析链接的关系,列举出各个链接源的ID及其所链接的目标ID。
链接源I D 链接目标 ID
1 | 1 2,3 ,4,5, 7 |
使用邻接矩阵的形式表述网页之间的链接关系,A[i][j]=1表示从i到j有链接,否则表示无链接,A为7*7的矩阵。
1 | A = [ |
我们现假设,每个网页初始的PageRank均为1,则会形成一个初始的PageRank转移矩阵。
1 | A = [ |
这样的话,我们就可以按照求马氏链平稳分布的方式,求得PageRank收敛结果,方程组为:
1 | X1 = X2 + X3 / 2 + X5 / 4 + X6 / 2 |
解这个方程,最终我们得到每个网页的PageRank收敛值分别为:
X1 = 0.303514,X2 = 0.38286,X3 = 0.32396,X4 = 0.24297,X5 = 0.41231,X6 = 0.10308,X7 = 0.13989。
将PageRank的评价按顺序排列,小数点3位四舍五入,可以得到下表:
1 | 名次 PageRank 文件ID 发出链接ID 被链接ID |
让我们详细地看一下。ID=1 的文件的 PageRank 是0.304,占据全体的三分之一,成为了第1位。特别需要说明的是,起到相当大效果的是从排在第3位的 ID=2 页面中得到了所有的 PageRank(0.166)数。ID=2页面有从3个地方过来的反向链接,而只有面向 ID=1页面的一个链接,因此(面向ID=1页面的)链接就得到了所有的 PageRank 数。不过,就因为 ID=1页面是正向链接和反向链接最多的页面,也可以理解它是最受欢迎的页面吧。
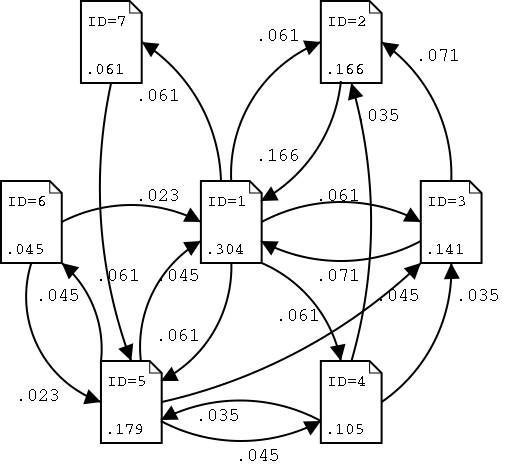
依据上图的PageRank值,我们实际地试着计算一下PageRank的收支,只要将自各页的流入量单纯相加即可。譬如 ID=1 的流入量为:
1 | ID=1的流入量=(ID=2发出的Rank)+(ID=3发出的Rank) + (ID=5发出的Rank) + (ID=6发出的Rank) = 0.166 + 0.141 / 2 + 0.179 / 4 + 0.045 / 2 = 0.30375 |
在误差范围内PageRank的收支相符合。其他页面ID的情况也一样。以上的 PageRank 推移图正表示了这个收支。沿着各自的链接发出的PageRank等于此页面原有的PageRank除以发出链接数的值,而且和各自的页面的PageRank收支相平衡。
不过,这样绝妙均衡的本身,对理解线形代数的人来说当然不会是让人惊讶的事情。因为这正是“特性值和固有矢量的性质”,总之这样被选的数值的组就是固有矢量。以上就是 PageRank 的基本原理。 Google 做的就是大规模地处理这样的非常特性值问题。
PS:LZ系保研,由于没有参加考研,像《线性代数》、《随机过程》好多年没摸过了,很多知识都有所遗忘,所以写的不深入。本文的一些内容是参考了别人的博客,自己又加入了些新元素,算是做一次探讨。当然,接下来LZ会开始复习一下相关的数学知识,后续会重写本文,以便于让本文显得更为Strong~
参考的相关博客地址:
http://www.charlesgao.com/?p=157
http://www.kreny.com/pagerank_cn.htm
本文地址:http://xnerv.wang/further-disscusion-of-pagerank-2/
转载自:深入探讨PageRank(二):PageRank原理剖析