背景
在MySQL 5.1中,如果配置项sync_binlog=1,并且innodb_flush_log_at_trx_commit=1,那么MySQL的TPS将会下降到几十每秒,完全不可接受。这是因为InnoDB提交事务时,不仅需要将REDO刷盘,还需要将Binlog刷盘,每个事务都需要2次sync操作。机械磁盘的IOPS也就为几百的水平,所以InnoDB的性能极差。
这个问题,在MySQL 5.6中得到了比较好的解决。在了解Binlog Group Commit之前,需要先了解MySQL Binlog和InnoDB的两阶段提交。MySQL为了保证主库和从库的数据一致性,就必须保证Binlog和InnoDB的一致性,即如果一个事务写入了Binlog,InnoDB中就必须提交该事务;相反,如果一个事务没有写入Binlog,InnoDB就不能提交该事务。做法是:

InnoDB先执行Prepare,将Redo日志写磁盘。然后再将Binlog写磁盘,最后InnoDB再执行Commit,将事务标记为提交。这样,可以保证Binlog和InnoDB的一致性。具体原因,可以分三种情况考虑:
情况1: 如果MySQL在InnoDB Prepare阶段Crash。MySQL在启动时做崩溃恢复,InnoDB会回滚这些事务,同时由于事务也没有写到binlog,InnoDB和Binlog一致。
情况2: 如果MySQL在Binlog写磁盘阶段Crash。MySQL在启动时做崩溃恢复,在恢复时会扫描未成功提交的事务,和当时未成功关闭的binlog文件,如果事务已经Prepare了,并且也已经在Binlog中了,InnoDB会提交该事务;相反,如果事务已经在Prepare中了,但是不在Binlog中,InnoDB会回滚该事务。结果就是InnoDB和Binlog一致。
情况3: 如果MySQL在InnoDB执行Commit阶段Crash,和情况2类似,由于事务已经成功Prepare,并且存在Binlog文件中,InnoDB在崩溃恢复时,仍然会提交该事务,确保Binlog和InnoDB一致。
MySQL在实现时,将mysql_bin_log作为2阶段提交的协调者,可以参考MySQL的代码:sql/handler.cc:ha_commit_trans。内部分别调用tc_log->prepare()和tc_log->commit()实现2阶段提交,这里的tc_log就是MySQL源码中的全局对象mysql_bin_log。
伪代码如下:
1 | ha_commit_trans() |
两阶段提交的参与者分别为:binlog_hton和innobase_hton,它们实现了MySQL的存储引擎接口。如果你再深入调研一下,就会发现binlog_hton在2阶段提交时,啥也没干。所有binlog操作都是由协调者mysql_bin_log干的,包括Group Commit,也都是在mysql_bin_log中实现的。下面我们就来分析一下,mysql_bin_log是如何做到Group Commit的,也就是上面的函数ordered_commit()。
实现
和Level DB的Group Commit类似,MySQL的Group Commit也是维护了一个队列,第一个进入队列的线程就是Leader,负责写binlog。其他的线程是Flower,Flower不需要操作,只需要等待完成的通知即可。但是如果只用一个队列的话,在Group Commit进行中的时候,后来的线程就得等待,还可以进一步优化,MySQL把这个过程分裂成了3个阶段:FLUSH_STAGE,SYNC_STAGE和COMMIT_STAGE。它们像流水线一样工作,每个阶段都会涉及一批事务,它们组成一个Group。可以这样理解,事务刚提交时,处于FLUSH阶段,同时处于FLUSH阶段的事务为一个队列,形成一个Group,只有队列的头,Leader在干活,FLUSH完成以后,Leader进入SYNC阶段(所有的Flower也都进入SYNC阶段)。这时,新提交的事务可以进入FLUSH阶段,它们又会产生一个新的Leader,如此不断的推进。每个阶段都需要一个队列,所以MySQL在Group Commit时,需要3个队列。如下图所示,队列通过thd->next_to_commit连接:
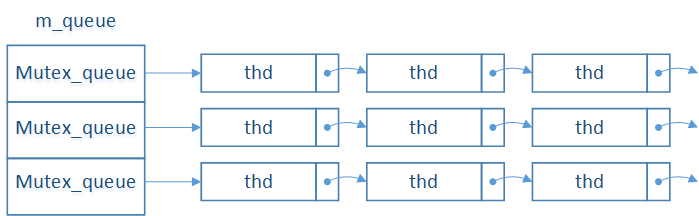
MySQL把队列命名为Mutex_queue,这是一个C++的类,定义如下:
1 | class Mutex_queue { |
在Group Commit时,事务的状态首先转为FLUSH_STAGE,然后为SYNC_STAGE,最后为COMMIT_STAGE。在状态转变时,都会调用如下函数Stage_manager::enroll_for:
1 | bool Stage_manager::enroll_for(StageID stage, THD *thd, mysql_mutex_t *stage_mutex) { |
从上面的代码可以看出,Flower线程什么也不干,所有的事情都要靠Leader去做。上述代码有一个细节需要注意,先把自己添加到队列中,然后再释放锁stage_mutex,这个在后面会有解释。下面逐个分析一下,在每个阶段Leader线程所做的事情。
FLUSH阶段
因为InnoDB在事务执行过程中,要保证事务的原子性。对于INSERT/UPDATE/DELETE操作,会先将Binlog写事务日志(binlog_cache_mngr),事务提交时,也就是在FLUSH阶段,再把事务日志复制到binlog文件中,然后通知Dump线程去发送binlog,由于要写Binlog文件,这个过程需要锁定LOCK_log锁。这也就是FLUSH阶段要做的事情,可参考函数:MYSQL_BIN_LOG::process_flush_stage_queue。
在这个阶段,Leader线程遍历遍历FLUSH_STAGE链表,依次取出thd对应的事务日志,并写到binlog的IOCACHE中,然后flush IOCACHE。代码如下:
1 | int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit) |
在这个过程中有一个问题需要考虑,就是:一方面,Leader线程从链表中取出thd,将日志写binlog IOCACHE,另一方面,新提交的事务仍然会往FLUSH_STAGE链表中添加thd。如果MySQL的并发事务比较多,Leader线程写binlog的速度,小于新事务的提交速度,可能会造成事务停留在FLUSH阶段的时间过长。所以MySQL通过配置项binlog_max_flush_queue_time来控制这个时间,如果Leader线程在取THD时,发现超时了,Leader线程就将队列整个端走,再做处理。这样,当前已经处于FLUSH阶段的事务还用现在的Leader,而新提交的事务,会用新的Leader。因为LOCK_log锁的存在,所有新的Leader只能等当前的FLUSH执行完成才能开始执行。具体代码如下:
1 | int MYSQL_BIN_LOG::process_flush_stage_queue(my_off_t *total_bytes_var, |
写完binlog IOCACHE后,还要将IOCACHE写文件,最后通知Dump线程读取binlog,FLUSH阶段完成。
SYNC阶段
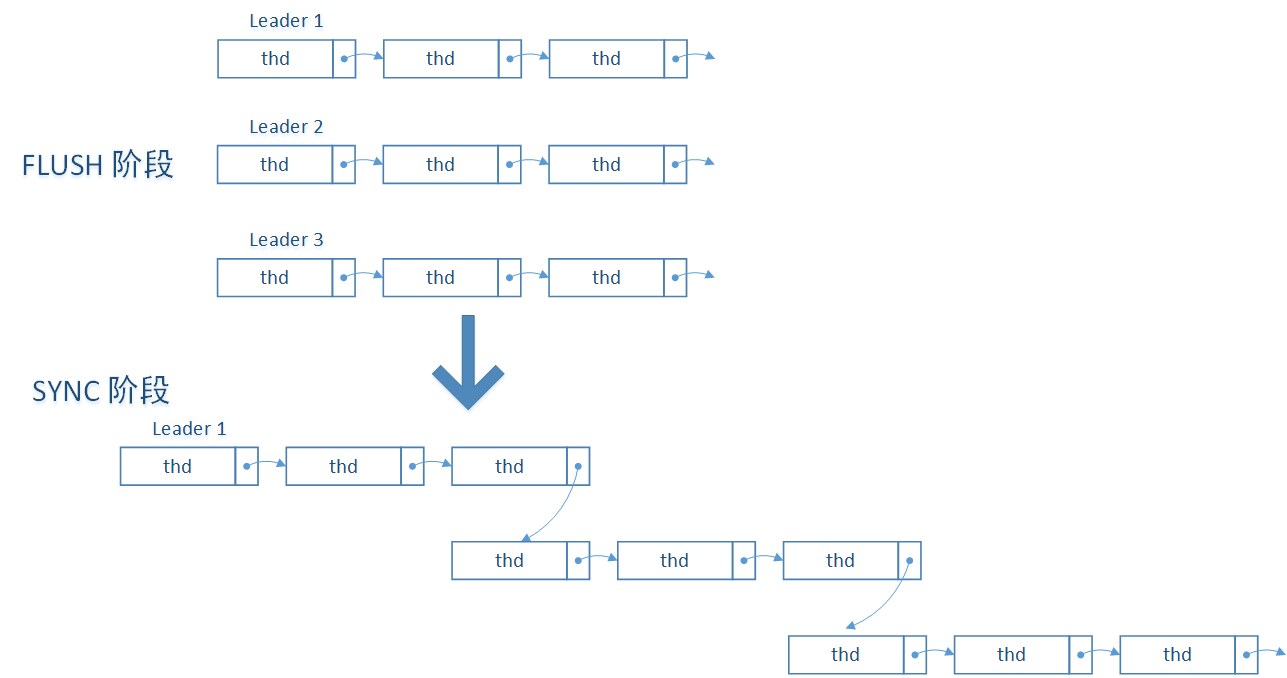
SYNC阶段的任务比较简单,但是却非常耗时,就是将binlog文件sync到磁盘。这个操作由配置项sync_binlog = N 来控制每隔N个binlog只sync一次。如果sync_binlog=1的话,MySQL在SYNC阶段不释放锁LOCK_log,而Dump线程为了读取binlog,必须先申请锁LOCK_log,所以可以保证主库先将binlog sync到磁盘,然后Dump线程才能读取Binlog,确保即使在主库操作系统Crash情况下,仍然保证主库和从库数据一致。其他情况会释放LOCK_log锁,这时Dump线程可以读取并发送binlog,同时新提交的事务也可以进入FLUSH阶段。所以SYNC阶段需要考虑有多个FLUSH阶段的Leader同时进入SYNC阶段的情况。MySQL将这些Leader合并为一个新的Leader,做法是:FLUSH阶段的Leader线程进入SYNC阶段前,需要将自己加入到SYNC_STAGE队列中,第一个进入SYNC_STAGE队列的线程为SYNC阶段的Leader,后进入的为Flower。由Leader完成后续操作,Flower线程只需等待通知即可。回忆前面的函数enroll_for(),在状态转变时,Leader先把自己添加到SYNC队列中,然后才释放锁stage_mutex,这里就是LOCK_log,其他事务才可以进入FLUSH阶段,这可以保证,第一个进入FLUSH阶段的Leader,在SYNC阶段仍然是Leader,同样,在COMMIT阶段还是Leader。这对于保证Binlog和InnoDB提交顺序一致非常重要。
SYNC阶段的代码如下:
1 | int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit) |
COMMIT阶段
经过前面2个阶段,Binlog已经顺利sync到磁盘了,COMMIT阶段的任务就是让InnoDB存储引擎完成Commit。COMMIT阶段的逻辑通过MySQL的配置项binlog_order_commits控制。如果配置项为1,MySQL要保证InnoDB的提交顺序和Binlog的写入顺序一致,这个特性在InnoDB热备中使用。下面只分析binlog_order_commits=1的情况。
MySQL释放锁LOCK_sync,申请锁LOCK_commit。由于释放锁LOCK_sync,所以需要考虑多个线程同时完成SYNC阶段的情况,处理逻辑和SYNC阶段类似,将当前SYNC阶段的Leader合并,关于Leader的产生和SYNC阶段类似。Leader产生以后,遍历THD,完成事务提交,等所有事务都提交完成以后,再遍历thd,设置thd->transaction.flags.pending=false,最后广播通知Flower线程提交完成,自此,Group Commit完成。
代码如下:
1 | int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit) |
Leader产生以后,Leader线程通过next_to_commit遍历thd,对每个thd完成事务提交ha_commit_low(),代码如下:
1 | void |
本文地址:http://xnerv.wang/implement-of-binlog-group-commit-in-mysql56/
转载自:MySQL 5.6中Binlog Group Commit实现