LevelDB 介绍
LevelDB 是由 Google 开发的 key-value 非关系型数据库存储系统,是基于 LSM(Log-Structured-Merge Tree) 的典型实现,LSM 的原理是:当读写数据库时,首先纪录读写操作到 Op log 文件中,然后再操作内存数据库,当达到 checkpoint 时,则写入磁盘,同时删除相应的 Op log 文件,后续重新生成新的内存文件和 Op log 文件。
LevelDB 内部采用了内存缓存机制,也就是在写数据库时,首先会存储在内存中,内存的存储结构采用了 skip list 结构,待达到 checkpoint 时,才进行落盘操作,保证了数据库的高效运转。
LevelDB 总体架构
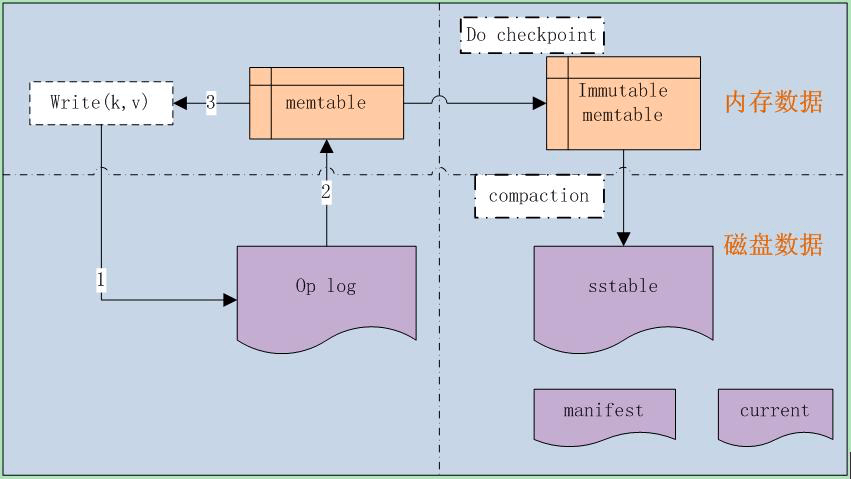
如上图所示,整个 LevelDB 由以下几部分组成:
- Write(k,v),对外的接口
- Op log,操作日志记录文件
- memtable,数据库存储的内存结构
- Immutable memtable,待落盘的数据库内存数据
- sstable,落盘后的磁盘存储结构
- manifest,LevelDB 元信息清单,包括数据库的配置信息和中间使用的文件列表
- current,当前正在使用的文件清单
整体结构清晰紧凑,非常容易理解。
对外接口
1 | DB() { }; |
整体接口分为:
- 数据库创建和删除
1 | DB() { }; |
- 数据库打开
1 | static Status Open(const Options& options, |
- 数据库读写删除操作
1 | virtual Status Put(const WriteOptions& options, |
- 数据库批处理操作
1 | virtual Status Write(const WriteOptions& options, WriteBatch* updates) = 0; |
- 数据库遍历操作
1 | virtual Iterator* NewIterator(const ReadOptions& options) = 0; |
- 获取快照操作
1 | virtual const Snapshot* GetSnapshot() = 0; |
Op log结构分析
LevelDB 使用的 Op log 日志采用了文件记录的方式,且文件使用了 mmap 方式操作,以提高效率。
Op log 存储切分为 32KB 大小的数据块,每个 32KB 数据块存储着 Op log,每 个Op log 格式如下:
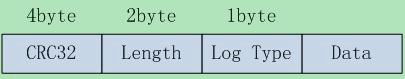
其中:
- CRC32 为 crc 校验码,保证数据的完整性
- Length,为 Op log 的数据长度
- Log Type,Op log 的类型,之所以会有类型,是由于 32KB 可能存不下一条 Op log,Op log 有可能跨数据块,类型分为:
- FULL:代表 Data 包含了所有的数据
- FIRST:代表该 Data 是 Op log 的开始数据
- MIDDLE:代表该 Data 是 Op log 的中间数据
- LAST: 代表该 Data 是 Op log 的结束数据
- Data,为 Op log 的实际数据
memtable 结构分析
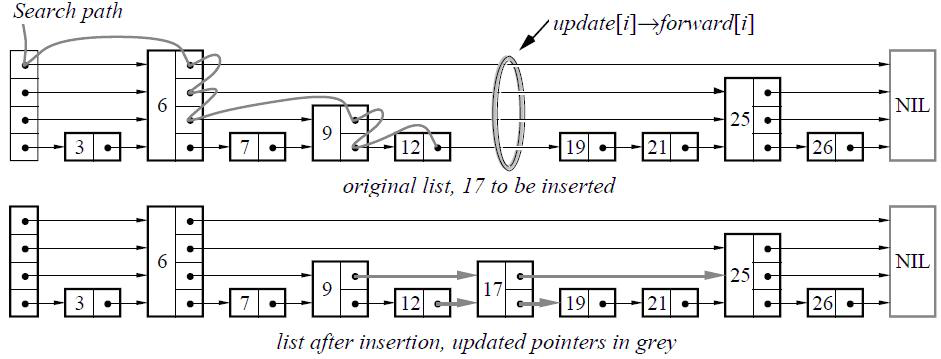
memtable 是 LevelDB 数据库的内存存储结构,采用了 skip list 结构存储,如下图所示:
skip list 是一种可以代替平衡树的存储结构,它采用概率的方式来保证平衡,而平衡树则是采用严格的旋转树结构来保证平衡,复杂度会高一些。
对于 skip list,会有 n 层链表,其中 0 层保存所有的值,越往上层,保存的值越少。每当插入一个值时,会通过概率计算该值需要插入的最高层级 k,然后从 0~k-1 层,分别插入该值。
其中每个表项的存储结构如下:
1 | key_size | key_value | sequence_num&type | value_size | value |
其中:
sequence_num:表示操作的序列号,每一个数据项都会带有一个序列号,用以表示数据的新旧程度。
type:表示数据的类型,分为:
- kTypeValue:表明数据有效
- kTypeDeletion:表明数据已经失效,在数据进行 delete 操作时会打上该标识
sstable 结构分析
sstable 作为落盘的存储结构,每个 sstable 最大 2MB,从宏观来看,它属于分层的结构,即:
- level 0:最多存储 4 个 sstable
- level 1:存储不超过 10MB 大小的 sstable
- level 2:存储不超过 100MB 大小的 sstable
level 3 及之后:存储大小不超过上一级大小的 10 倍
之所以这样分层,是为了提高查找效率,也是 LevelDB 名称的由来。当每一层超过限制时,会进行 compaction 操作,合并到上一层,递归进行。
从微观的角度看,每个 sstable 文件结构入下图所示:
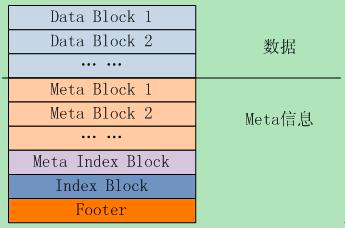
其中:
- Data Block 存储具体的 k-v 数据
- Meta Block 存储索引过滤信息,用于快速定位 key 是否存在于 Data Block 中
- Meta Index Block 存储 Meta Block 的偏移位置及大小
- Index Block 存储 Data Block 的偏移位置及大小
- Footer 则存储 Meta Index Block 和 Index Block 的偏移位置及大小,相当于二级索引,Footer 的结构如下:

另外 Data Block 及 Meta Block 的存储格式是统一的,都是如下格式:

其中 type 表示是否是压缩存储,目前 LevelDB 支持 key 值的 snappy 压缩或者不压缩。
而上图中的 Block data 的格式则为:

上图有几点要说明:
- 对于 Block data 中的第一项总是不压缩存储的,不压缩存储的项称为 restarts,会被记录在上图的最尾部,同时每隔 k 个值(k 值可定制),都会存储一个不压缩的项,这些都称为 restarts,都会被记录在最尾部。
- 每个 restarts 表项会作为索引项存储。
- 除了 restarts 表项以外,其它的表项则基于该 restarts 项,计算跟他相同部分和不同部分,上图中的 shared_bytes 和 unshared_bytes 记录了相同部分长度和不同部分的长度,key_delta 则记录了不同的部分的值,value_length 和 value 则记录了 value 部分的值。
- 压不压缩是可选的,默认会进行 snappy 压缩。
对于 Meta Block 来说,它保存了用于快速定位 key 是否在 Data Block 中的信息,具体方法是:
- 采用了 bloom filter 的过滤机制,bloom filter 是一种 hash 机制,它对每一个 key,会计算 k 个 hash 值,然后在 k 个 bit 位记录为 1。当查找时,相应计算出 k 个 hash 值,然后比对 k 个 bit 位是否为 1,只要有一个不为 1,则不存在。
- 对于每一个 Data Block,所有的 key 值会传入进行 bloom filter 的 hash 计算,每个 key 存储 k 个 bit 位值。
版本管理
对于 LevelDB 来说,它采用了简单的 sequence num 机制来管理,具体为:
- 对于 Op log 文件,每一个 Op log 文件名中会包含一个唯一的 sequence num,每创建一个新的 Op log 文件,sequence num 则加 1,sequence num 越大,则表示文件越新,同时最新的 sequence num 会记录下来。
- 对于每个 key-value 对,也会对应一个 sequence num,对于同一个 key,如果后续更新值时,sequence num 也会相应更新,这样就可以根据 sequence num 的大小,找到最新的 key-value 对
新增特性
-
支持模糊查询
该功能支持 key 以模糊规则匹配的方式进行数据库查询,支持*和?两种模糊规则查询。
-
支持 JSON 格式数据存储
该功能支持 k-v 中,v以json格式传入,后续可以通过关键字,查询json里面的数据。
结束语
LevelDB 短小精悍,代码运行效率高效,且通俗易懂,是一个非常不错的 k-v 存储系统。
注:图片来源于网络
题图:https://unsplash.com/photos/9wwF-VmSOrY By @eberhard grossgasteiger