In this article, I am going to describe some general features and some specific ones of the memory management in Linux. It will be mainly on dynamic memory allocation and release, as well as the management of the free memory. The article concerns the Linux kernel versions 2.6.X.
Structure of the Linux memory management
The term “memory management” refers to the mechanisms implemented by an operating system to provide applications with memory-related services. These services include usage of virtual memory (utilizing of a hard disk or other non-RAM storage media to provide additional program memory), protected memory (exclusive access to a region of memory by a process), and shared memory (cooperative access to a region of memory by multiple processes).
Memory management services in the Linux are built on a programming foundation that includes a peripheral device called Memory Management Unit (MMU). MMU translates physical memory addresses to linear addresses used by the operating system, and requests a page fault interrupt, when the CPU tries to access memory that it is not entitled to.
Not all processors have MMUs. Therefore, the uClinux distribution (Linux for microcontrollers) supports a single address space of operation. This architecture lacks the protection provided by MMU but makes it possible for Linux to run on another class of processors.
For further understanding of structure of the MM services, we need to know that a basic unit of memory under Linux is page, a non-overlapping region of contiguous memory. All available physical memory is organized into pages towards the end of the kernel’s boot process. Size of page depends on processor architecture. Processor designs often allow to have two or more, sometimes simultaneously, page sizes.
Traditional page size used by Linux is 4096 bytes.
But using memory pages “as is” is not very convenient. Often we need to allocate less than one memory page. There are such possibilities in Linux:
- in the kernel, you can allocate one of the small kernel objects using slab allocator;
- you can allocate a memory block by kmalloc, but it will allocate only a block of the nearest bigger size that it has;
- in the user mode, you can allocate any amount of memory using heap management functions implemented in Standard C Library;
- you can create your own heap manager on top of the Linux kernel system calls.
To provide a simple interface for interaction with Memory Management Unit and perform such interaction in a portable way, in Linux, subsystem of allocating and releasing memory is split into three layers. These layers are:
- The Slab Allocator
- The Zone Allocator
- The Buddy Allocator
General scheme of all these layers interaction with user mode code and hardware looks as follows:
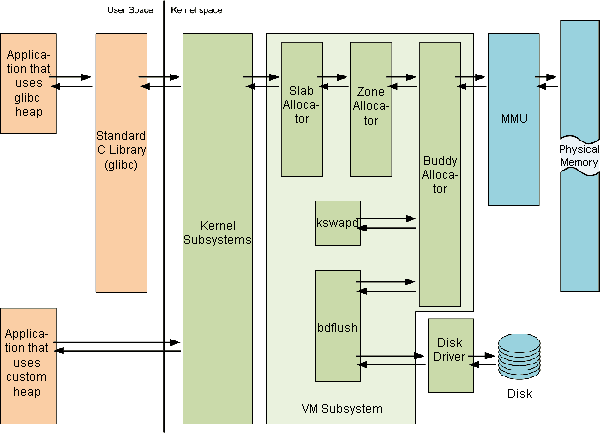
Figure 1. General scheme of the memory management in Linux
Note that in Linux, most of programs directly or indirectly use heap manager of the GCC Standard C Library called glibc, but you still can write your own heap manager on top of the kernel system calls.
As we can see on the Figure 1, user space allocation always leads to kernel allocation. Kernel allocates memory using the chain of three kernel allocators and maps allocated pages to the address space of the process, which has requested the allocation.
Kernel mode memory management services
The Buddy Allocator is responsible for the management of the page allocations in the entire system. This code manages lists of physically contiguous pages and maps them into the MMU page tables to provide other kernel subsystems with the valid physical address ranges, when the kernel requests them (Physical to Virtual Address mapping is handled by a higher layer of the VM).
The Buddy Allocator splits memory into pairs of 2n pages where n is in range from 0 to MAX_ORDER constant (defined in the header file <linux/mmzone.h>), and stores information about the free blocks of pages in the array of lists as follows:
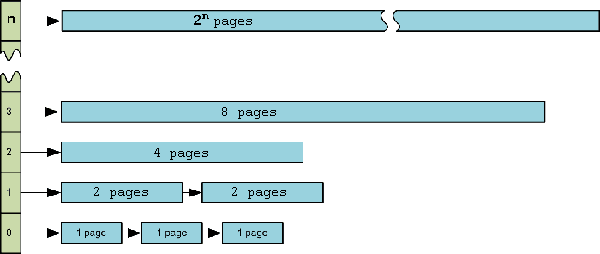
Figure 2: Array of lists of memory pages in the Buddy Allocator
Each list consists of free physically contiguous blocks of 2i memory pages, where i is a list number. Each of such blocks, except the block that consists of 1 page, can be split into two halves and used as 2 blocks of a half size.
So if no entries exist in the requested list, an entry from the next upper list is broken into two separate clusters and one is returned to the caller while the other one is added to the next lower list.
On the other hand, every two blocks of memory of the same size, which have common border (arranged in memory sequentially, from the standpoint of physical addresses), may be united into the single block of the bigger size. Such neighboring blocks are called Buddies.
When allocation is returned to the Buddy Allocator, it checks if buddy of the allocation is free, and if it is so, Buddy Allocator unites them into the bigger block. This operation is repeated until no more block buddies are found.
Also we should note that the Buddy Allocator can allocate only blocks of the size in pages that is equal to 2 raised to some power.
The Buddy Allocator also interacts with the kernel threads kswapd and bdflush, which are responsible for the maintaining with the swap.
Different ranges of physical pages may have different properties, for the purposes of the kernel. For example, Direct Memory Access can work only in specific range of physical addresses in the x86 architecture. On the other hand PPC does not have this constraint.
For handling such situation in a hardware, independent way the Zone Allocator was created.
The Zone Allocator is used to allocate pages in the specified zone. Today Linux kernel is supporting three memory zones:
- DMA — This zone consists of memory accessible for direct memory operations of the legacy devices
- NORMAL — This zone includes memory addresses used by the kernel for internal data structures as well as other system and user space allocations.
- HIGHMEM — This zone includes all memory used exclusively for system allocations (file system buffers, user space allocations, etc).
Note that the Zone Allocator also can manipulate only with memory pages.
Since we often need to allocate objects that have size less than the size of a page, we need something to deal with the pages and allocate lesser chunks of memory for us.
We know the sizes of the most objects that are often allocated in the kernel space, so we can create allocator that will receive pages of memory from the Zone Allocator and allocate small objects in these memory pages. This subsystem is named the Slab Allocator (An Object-Caching Kernel Memory Allocator).
The Slab Allocator organizes memory in caches, one cache for each object type, e.g. inode_cache, dentry_cache, buffer_head, vm_area_struct. Each cache consists of many slabs (usually one page long), and each slab contains multiple initialized objects.
This means that the constructor of the objects is used only for newly allocated slabs and you should initialize object before release it to the Slab Allocator.
Also the Slab Allocator makes it possible to allocate buffers of memory of one of the specially defined sizes. Such buffers can be got using kernel function kmalloc. You specify the size of allocation, and kmalloc will allocate block of the greater size, the nearest to the one you requested. Sizes of memory blocks, which can be allocated by kmalloc, are available in the header file <linux/kmalloc_sizes.h>.
Also the kernel can allocate virtually contiguous memory (memory with contiguous virtual addresses, but not with contiguous physical addresses) using vmalloc function.
Special aspects of the linux kernel mechanisms of the memory management
Why Linux developers rarely check results of memory allocation.
The short answer is: “Because of overcommit”.
Under the default memory management strategy, malloc (and kmalloc, and vmalloc) always succeeds, even if the system has not enough memory to satisfy the request. The Linux kernel assumes that you’re not going to use all of the memory you asked for. Real allocation occurs only when you get access to the allocated memory, and if the system does not have enough free memory then it will run Out-of-memory (OOM) killer. OOM killer will try to free some memory for you, killing other processes and releasing their memory or it will kill your process if it deems the task you are performing to have a lower priority.
This approach leads to some performance gains for applications, which allocate a lot of memory but use only some part of it, since allocation of the swap pages will not be performed before the swap pages is used.
But sometimes such approach is not good because of the chance to be killed by OOM killer at any moment. Fortunately, Linux allows to change default approach of the memory allocation and behavior of the system when the OOM event occurs.
The overcommit policy is set via the sysctl vm.overcommit_memory.
The Linux kernel supports the following overcommit handling modes associated with the values of the kernel parameter vm.overcommit_memory:
-
Heuristic overcommit handling. Obvious overcommits of address space are refused. This type of handling is used for a typical system. It ensures a seriously wild allocation fails while allowing overcommit to reduce swap usage. Root is allowed to allocate a bit more memory in this mode. This type is set by default.
-
Always overcommit. Appropriate for some scientific applications, which use a lot of memory.
-
Don’t overcommit. The total address space commit for the system is not permitted to exceed swap + a configurable percentage (50% by default) of physical RAM. Depending on the percentage you use, in most situations, this means that a process will not be killed while accessing pages but will receive errors on memory allocation as appropriate.
The overcommit percentage is set via the sysctrl vm.overcommit_ratio.
The current overcommit limit and amount committed can be viewed in /proc/meminfo as CommitLimit and Committed_AS respectively.
How Out-of-memory killer mechanism works
There are three strategies to handle Out-of-memory situation:
- Kill allocating process
- Kill some other process or processes to allow allocating process get the memory
- Stop the system and show message about kernel panic.
The first and the third strategies are fairly simple unlike the second strategy. Let’s consider it in more detail.
According to the second strategy, Linux will try to choose appropriate process to kill when it runs out of memory. “Appropriate” in this context means that:
- User will lose the minimum amount of work done
- System will recover a large amount of memory
- OOM killer don’t kill process that has not allocated a lot of memory
- OOM killer intends to kill the minimum number of processes (to kill just one process would be the best)
- OOM killer will kill the process the user expects it to kill
In order to choose a process to kill, OOM killer calculates the value named Badness. Then it selects the process with the maximum Badness to be killed. If the allocating process was chosen, OOM terminates its work. If some other process was chosen, OOM killer can be called more than once in case of previous run of the OOM killer did not free enough memory.
Badness is calculated according to the next rules:
- Initial badness of the process A is the size of the virtual memory allocated for it plus a half of size of the virtual memory allocated to the child processes of the process A;
- Initial badness is divided by the square root of the CPU time consumed by the process A measured in tens of seconds;
- Result is divided by the root with index 4 of the run time of the process A measured in thousands of seconds.
- If the process A has “nice” greater than zero (priority is lower than normal), badness of the process A is multiplied by 2;
- If the process A was started with the root privileges, badness of the process A is divided by 4;
- If the process A performs raw IO, badness of the process A is divided by 4;
- If memory usage of the process A might not impact the memory available to the process, which has initiated OOM procedure, then badness of process A is divided by 8;
We can write badness of the process A as the equation:
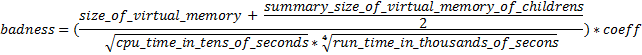
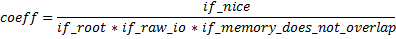
Where:
if_nice can be either 1 or 2 according to the nice of the process (2 if nice > 2 or 1 otherwise)
if_root can be 1 or 4 ( 4 if the process A has root privileges or 1 otherwise )
if_raw_io can be 1 or 4 ( 4 if process has capability to perform raw IO or 1 otherwise )
if_memory_does_not_overlap can be 1 or 8 ( 8 if the process A has no memory that can be allocated to the process, which has initiated OOM procedure).
You can see the mechanism of the out-of-memory handler in the source file “/mm/oom_kill.c” in the Linux kernel sources tree.
You can tune OOM handling mechanism by setting values to such kernel parameters:
vm.oom_dump_tasks
This parameter enables a system-wide task dump (excluding kernel threads) to be produced when the kernel performs an OOM-killing and includes such information as pid, uid, tgid, vm size, rss, cpu, oom_adj score, and name. It is helpful to determine why the OOM killer was invoked and to identify the process that caused it.
If it is set to zero, this information is suppressed.
If it is set to non-zero, this information is shown whenever the OOM killer actually kills a memory-hogging task.
By default vm.oom_dump_tasks is set to 1;
vm.oom_kill_allocating_task
This parameter enables or disables killing the OOM-triggered task in out-of-memory situations.
If this parameter is set to non-zero, the OOM killer simply kills the task that triggered the out-of-memory condition. It helps to avoid the resource-expensive tasklist scan and makes OOM killer very predictable.
If it is set to zero, the OOM killer will scan through the entire tasklist and select a task on the basis of the badness calculation.
By default vm.oom_kill_allocating_task is set to 0;
vm.panic_on_oom
If this kernel parameter is set to 1 the kernel panics occurs at out-of-memory situation. But, if a process is limited by nodes by mempolicy/cpusets, and those nodes get memory exhaustion status, one process may be killed by OOM killer. No kernel panic occurs in this case, because other memory nodes can be free.
If this parameter is set to 2, the kernel panic is forced even in the above-mentioned situation. Even if OOM happens under the memory cgroup, the whole system panics.
If this parameter is set to 0, the kernel will kill some processes when OOM happens.
By default vm.panic_on_oom is set to 0;
Note that panic_on_oom has higher priority than oom_kill_allocating_task.
Additional links and literature:
- Anatomy of the Linux slab allocator http://www.ibm.com/developerworks/linux/library/l-linux-slab-allocator/
- Understanding Virtual Memory http://www.redhat.com/magazine/001nov04/features/vm/
- When Linux Runs Out of Memory http://linuxdevcenter.com/pub/a/linux/2006/11/30/linux-out-of-memory.html
- Andries Brouwer, The Linux kernel http://www.win.tue.nl/~aeb/linux/lk/lk-9.html
- Ops monkey blog entry “Linux memory overcommit” http://opsmonkey.blogspot.com/2007/01/linux-memory-overcommit.html
- Outline of the Linux Memory Management System http://www.thehackademy.net/madchat/ebooks/Mem_virtuelle/linux-mm/vmoutline.html
- Linux kernel documentation: sysctl/vm.txt and vm/overcommit-accounting
- Daniel P. Bovet Marco Cesati “Understanding the Linux Kernel”, O’Reilly ISBN: 0-596-00002-2, 702 pages
本文地址:http://xnerv.wang/special-features-of-linux-memory-management-mechanism/
转载自:Special features of Linux memory management mechanism