为什么PostgreSQL要使用OS缓存?
与MySQL等开源数据库不同的是,PostgreSQL(PG)并不使用O_DIRECT来写data文件,而是依赖于OS缓存,并且强调在设置shared buffer在大小时不能过大,否则会造成过于频繁的swap而导致IO性能下降。这与MySQL等数据库的buffer pool size越大性能越好的指导原则是相反的。并且PG依赖于OS缓存的这一特性也给提供PostgreSQL云服务造成了很多问题。例如云服务要求multiple tenants资源隔离,也就是说跑在同一个VM上的多个PG servers相互之间不能互相影响,但共用OS缓存显然会造成资源竞争。不知道Docker是否可以进行OS缓存的资源隔离,但现阶段还还依赖于Service Fabric架构的Azure PG显然得自己解决这个问题,也因此造成了架构设计上不得不考虑OS缓存的隔离。
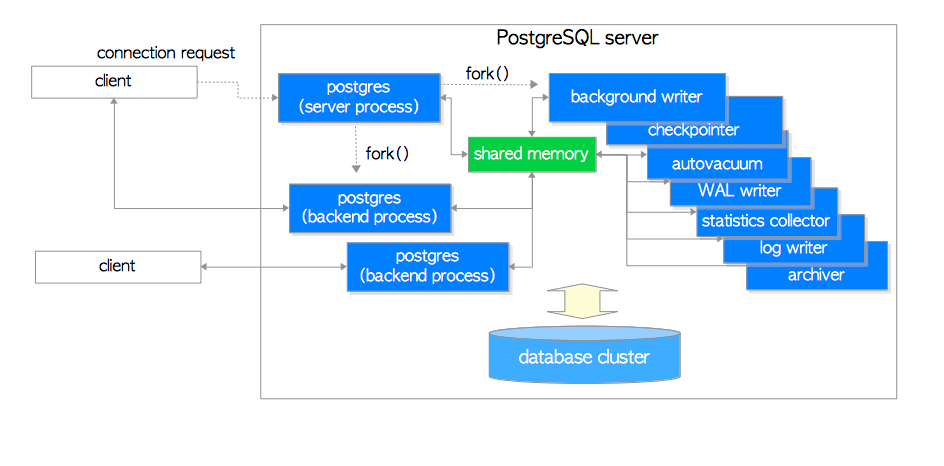
从The Internals of PostgreSQL: Chapter 2 Process and Memory Architecture这篇文章看来,与MySQL使用多线程或线程池和架构不同的是,PG使用的是多进程架构。多进程模型在Windows平台上会造成很大的性能问题,这暂且不提。但多进程之间是共用的shared buffer。既然如此,那就应该不是寄希望于OS缓存来便于多进程之间共享shared buffer吧。
PgSQL和MySQL的bufferpool探讨这篇文章提出了一种猜想,认为由于PostgreSQL是诞生在实验室中,主要为了研究数据库内核原理,那么使用buffer io能够减少IO栈的代码开发,进而能够减少额外的debug。这种说法是有可能的、虽然PG的代码比MySQL的干净太多,MySQL的代码中经常有类似xxx_function,xxx_function2,another_xxx_function2这种奇怪的函数名字,而且毫无注释完全不明所以。但是PG很明显在工程化和成熟度上不如MySQL。文章中提到PG中有这么一段代码:
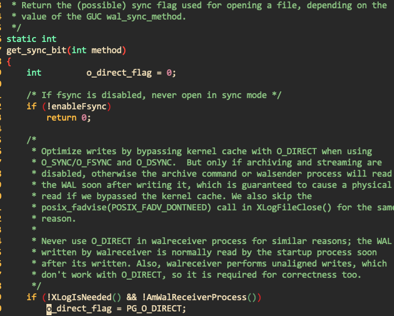
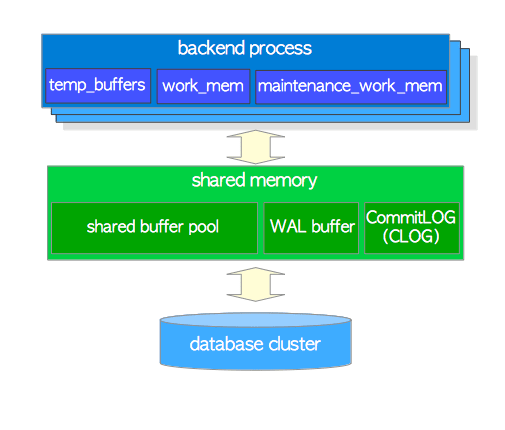
也就是说PG依赖于OS缓存来减少日志归档和流复制中的文件IO读取次数。但这应该仅限于WAL xlog文件。对于shared buffer pool,是什么原因使得还需要保留这种double buffering的设计呢?
The Internals of PostgreSQL: Chapter 8 Buffer Manager提到可以参考Why we are going to have to go DirectIO这篇讨论和Thread summary: the Linux kernel and PostgreSQL这篇文章。目前看来,应该还是PG的storage layer实现上过于简陋,效率上存在很大的问题,不足以脱离OS缓存而独自运行。这也印证了PgSQL和MySQL的bufferpool探讨这篇文章的说法。Understanding caching in Postgres - An in-depth guide这里也提到,PG依赖于OS缓存来调度写请求,这恐怕也是PG storage layer本身缺乏相应调度机制的一种表现。
PostgreSQL pain points中也有提到flow fsync和double buffering等问题,看起来PG的developers依赖于Linux kernel提供相应的解决方案。我不知道这是否是一种正确的方向,毕竟这种与特定OS紧耦合的方案也就限制了PG在其它OS平台上运行的能力。但是考虑到现在PG本来就在Windows上跑得很差像个demo,如果PG本身的开发力量不够的话,也许这也算是一种解决方案吧。