同学们工作之余,不妨放下微博跟朋友圈,来这10个网站感受一下看着就醉了的情境:「念完往上一推音乐键,我往后一靠,潮乎乎的软皮耳机里头,音乐排山倒海。」今天推荐的网站,利用代入感强的图片与音频,迅速帮你抹平焦虑,获得平和心态,特别献给改稿千遍的设计师们。
The Google File System——论文详解(转载)
“Google文件存储系统(GFS)是构建在廉价服务器之上的大型分布式系统。它将服务器故障视为正常现象,通过软件方式自动容错,在保证系统可用性和可靠性同时,大大降低系统成本。
GFS是Google整个分布式系统的基石,其他存储系统如Google BigTable、GoogleMegastore等系统均直接或间接构建在GFS之上。另外,Google的大规模批处理系统MapReduce也是利用GFS系统作为海量数据的输入输出。”
以下内容为在研读Google_File_System论文时,对其中一些关键技术的理解。要想更加深入的理解GFS,还需进一步研究GFS源码以及论文等。
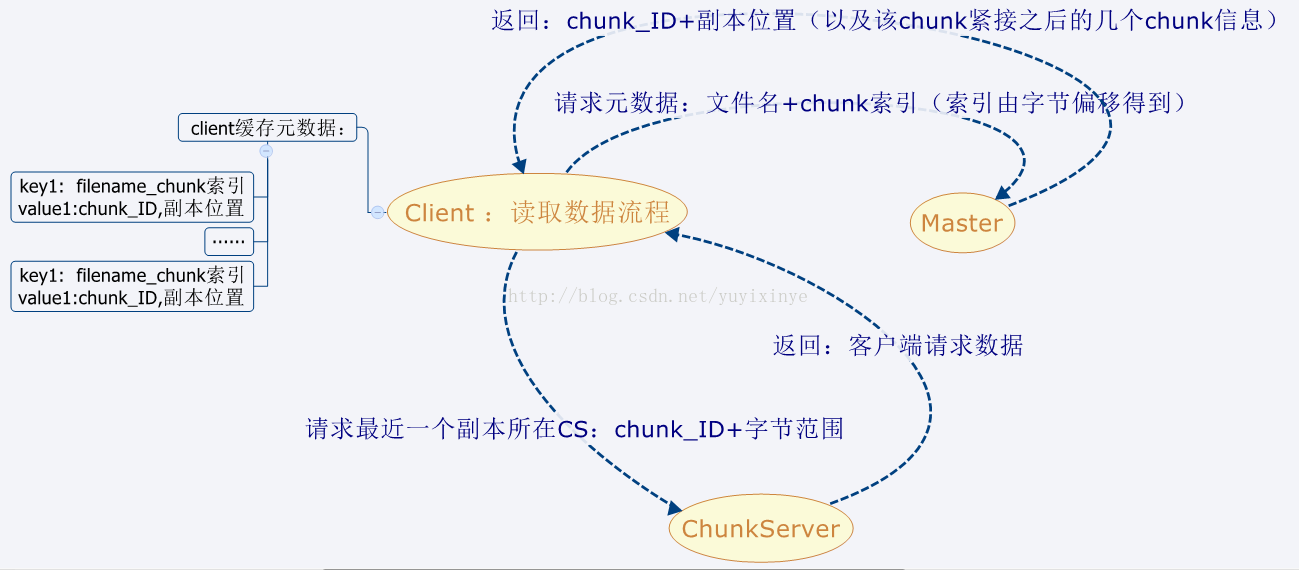
一、单一Master节点:
如何避免单一的Msaster节点成为系统性能瓶颈:
- 客户端只向Master请求元数据信息,并不通过Master节点进行chunk数据读写,具体的数据读写操作由ChunkServer直接负责。
- 客户端在向Master请求某chunk元数据时,Master会一次返回包括该chunk紧接之后的几个chunk信息,有效减少客户端的请求次数。
客户端读取数据流程如下:
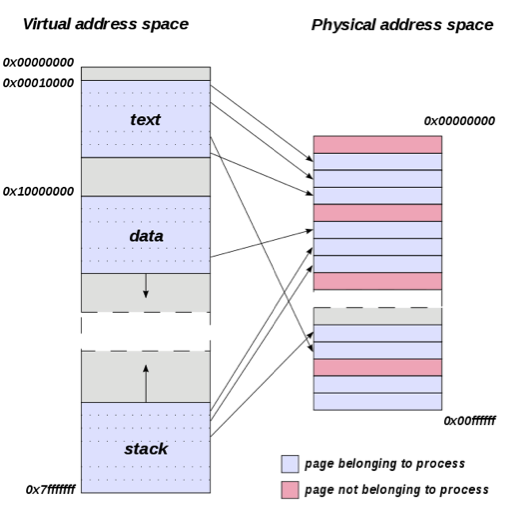
Special features of Linux memory management mechanism(转载)
In this article, I am going to describe some general features and some specific ones of the memory management in Linux. It will be mainly on dynamic memory allocation and release, as well as the management of the free memory. The article concerns the Linux kernel versions 2.6.X.
进程分配内存的两种方式--brk() 和mmap()(不涉及共享内存)(转载)
如何查看进程发生缺页中断的次数?
用ps -o majflt,minflt -C program命令查看。
majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
发成缺页中断后,执行了那些操作?
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
- 检查要访问的虚拟地址是否合法
- 查找/分配一个物理页
- 填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
- 建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
Memory Allocation Mechanism in Linux(转载)
Each Linux process has its own dedicated address space dynamically translated into physical memory address space by the MMU (and the kernel) [1]. To each individual process, the view is as if it alone has full access to the system’s physical memory [2]. More importantly, the address space of even a single process can be much larger than physical memory. However, the memory usage of each process is bounded with Linux resource limitation (via setrlimit()).
在调试器中看阿里的软件兵团(转载)
摘要:为了抢占用户桌面,很多客户端软件都是主动送上门的,不需要花钱购买。可能只要你一个认可,就在电脑上安家落户。住下来之后,有些软件偶尔动动,但也有些高调强势,让你不得不注意到它,本文要谈的就是这样的软件。
【协程原理】 - 协程不过是用户态的线程(转载)
笔者最美好的记忆来自于早年在6502 cpu的cc800上写汇编的年代, 那个时代的计算机甚至没有操作系统,也没有实模式等保护机制。在6502上写汇编应用其实非常简单,系统会把bin文件加载到一个固定的内存地址中,cpu会固定地从一个特定的位置开始执行。然后cpu就按照你提供的机器指令开始一条一条的执行。在高级语言中的“函数调用”的概念,在汇编里主要体现为两个寄存器。寄存器是cpu内部临时保存数据的区域,相当于高级语言里的变量。但是有一个寄存器是特殊的,它存放了cpu当前正在执行的指令的内存地址(Instruction Register)。一个高级语言中的函数一般会被编译成指令存放在一段连续的内存空间中(data segment)。那么所谓函数执行到了第几行这样的信息其实就是保存在这个Instruction Register中的。另外一个很特殊的寄存器是Stack Register,它其中存放的内存地址指向的内存区域用于函数之间传递参数和返回值,以及存放一个函数内的局部变量。如果不考虑现代计算机cpu中各种各样其他存放中间结果的寄存器,理论上保存了Instruction Register(执行到哪儿了)和Stack Register(堆栈上的变量)就保存了一个函数的当前执行状态,分别是函数当前执行到了哪,以及这个函数局部变量所代表的当前state。
如何实现一个malloc(转载)
任何一个用过或学过C的人对malloc都不会陌生。大家都知道malloc可以分配一段连续的内存空间,并且在不再使用时可以通过free释放掉。但是,许多程序员对malloc背后的事情并不熟悉,许多人甚至把malloc当做操作系统所提供的系统调用或C的关键字。实际上,malloc只是C的标准库中提供的一个普通函数,而且实现malloc的基本思想并不复杂,任何一个对C和操作系统有些许了解的程序员都可以很容易理解。
这篇文章通过实现一个简单的malloc来描述malloc背后的机制。当然与现有C的标准库实现(例如glibc)相比,我们实现的malloc并不是特别高效,但是这个实现比目前真实的malloc实现要简单很多,因此易于理解。重要的是,这个实现和真实实现在基本原理上是一致的。
这篇文章将首先介绍一些所需的基本知识,如操作系统对进程的内存管理以及相关的系统调用,然后逐步实现一个简单的malloc。为了简单起见,这篇文章将只考虑x86_64体系结构,操作系统为Linux。
16个很有用的在线工具(转载)
1. ExplainShell.com 命令解释

对于 Linux 用户来说每天都会写各种命令和脚本,那么你可以使用这个网站工具来查看命令式如何工作的,这样可以避免不必要的错误出现;也是一个很好的学习命令的方式。
2. BashrcGenerator.com 定制个性命令提示符

简单说就是个性化生成命令提示符,可将生成的代码写入到用户家目录的 .bashrc 或者可以设置全局变量文件/etc/profile 对所有用户生效。
可参考:http://stackoverflow.com/questions/4133904/ps1-line-with-git-current-branch-and-colors
每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)(转载)
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简 单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。